
The Tower of Hanoi
The Tower of Hanoi is a mathematical puzzle, often introduced to undergraduate college students. At face value, the puzzle seems pointless. You are simply moving discs around. Yet, something is interesting about the puzzle’s nature. After careful inspection, it turns out we can conjure up a concise recursive algorithm. If your not familiar with recursion, consider checking out my previous post. In a nutshell, recursion is useful when a problem can be broken down into smaller problems of the same form as the original. With some imagination, the Tower of Hanoi meets this requirement.
Why?
And you may be wondering why you should care. After all, there is an iterative solution to the puzzle—just do a Google search. Well, this toy problem shows that recursion can inspire simpler code than iteration. Although I’m not going to cover the iterative solution explicitly here, you should look it up. By comparing the two solutions, it’s clear that the recursive one features less code and easier to read.
Given the paragraph above, I am going to emphasize that recursion isn’t a superfluous, complicated technique. It has legitimate uses in the real world. If it will make your code easier to write and understand, consider using it. Now, it’s not always better. You should also be aware of the performance tradeoffs—particularly in languages without tail call optimization.
The Rules
For those unfamiliar with the puzzle, I’ll quickly explain the rules. There is a board with three poles and an arrangement of disks. The disks are each of a different size, and initially, they are arranged in a cone shape on a single pole. The goal is to move all the disks–one at a time–to another a pole, once again forming the cone shape. Also, a larger disk cannot be stacked on top of a smaller disk at any time.
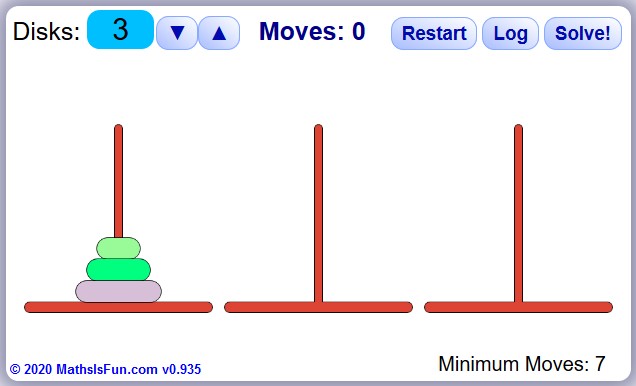
Recursive Solution
Once again, the Tower of Hanoi can be solved recursively. It works because we can split the game into subpuzzles. These subpuzzles are themselves a miniversion of The Tower of Hanoi–which can then be solved in the same fashion as the bigger version. To note, the algorithm will always produce a valid set of game-winning moves. So you can win the game every time.
Before jumping into the code, let’s imagine what the solution’s structure could look like. To start, we’ll label the three poles A, B, and C. Then, let’s say there’s a stack of h disks on pole A. This arrangement is the initial setup–no surprises here. As a reminder, to win, the player needs to move all the disks to another pole.
Yet, to move pole A’s largest disk, h-1 disks need to be shuffled to an auxiliary pole–let’s say pole B. Of course, this is just solving a slightly smaller version of the same puzzle. So, we need to move h-2 disks somewhere… You should see where this is going.
What happens when we have reduced our way to subpuzzle consisting of one disk? This situation is the easiest to handle–just move directly move the disk to the target pole–in this case pole C.
Now, in general, once the largest disk of a subpuzzle has moved been moved the target pole, we can then move all the disks placed on the auxiliary pole over to the target pole as well. To do this, we are again just solving a smaller version of the puzzle–we are just changing which poles are labeled as the auxiliary and the target.
In summary, we are repeatedly moving the large disk of a subpuzzle after the smaller disks above have been moved to the auxiliary pole. The key is to correctly track which poles should be the target and the auxiliary as the algorithm twists through the self calls. Assuming we do this correctly, the puzzle will be solved by solving all the subpuzzles in turn.
Some Code
Let’s stop talking theory and look at some code. Below, I wrote a solution in Racket that allows you to change the number of disks. Since immutable data structures are used, the code is a little different than what you typically find on the Internet; however, the core concepts are still the same. You should be able to map my natural language description to the code. At the very least, note what the base case is and how the problem space is reduced every self call.
#lang racket
(struct board (A B C) #:transparent)
(define (new-board size)
(board (range 1 (add1 size)) '() '()))
(define (pop stack)
(cond
[(empty? stack) '()]
[else (cdr stack)]))
(define (peak stack)
(cond
[(empty? stack) '()]
[else (list (car stack))]))
(define (move brd pole1 pole2)
(define table
(hash 'A (board-A brd)
'B (board-B brd)
'C (board-C brd)))
(define (check stack pole)
(cond
[(eq? pole pole1) (pop stack)]
[(eq? pole pole2) (append (peak (hash-ref table pole1)) stack)]
[else stack]))
(board (check (board-A brd) 'A) (check (board-B brd) 'B) (check (board-C brd) 'C)))
(define (solve size)
(cond
[(<= size 2) (raise-user-error "Size must be greater than two")]
[else
(define board (new-board size))
(helper size board 'A 'C 'B)]))
(define (helper n brd source target auxiliary)
(cond
[(n . > . 0)
(define new-brd-1 (helper (sub1 n) brd source auxiliary target))
(define new-brd-2 (move new-brd-1 source target))
(displayln new-brd-2)
(helper (sub1 n) new-brd-2 auxiliary target source)]
[else brd]))
(module+ main
(solve 3))Here’s the output from the code–with the size parameter set to three. The left-hand side is the top of each stack. With a little squinting, you should be able to trace out the correct series of moves to solve the puzzle.